
快科技6月26日音问万博manbext体育官网娱乐网,如今AI算力多如牛毛,然而一直存在诸多制约,其中很严重的少量就是“内存墙”,也就是内存带宽普及的速率远远跟不上算力需求,即等于HBM高带宽内存也经常力不从心,况且HBM的发烧越来越严重。
高通在投资者日上公开了新的高带宽考虑近内存架构“HBC”,尝试冲突内存墙,从而让特定AI负载齐备性能的线性普及。
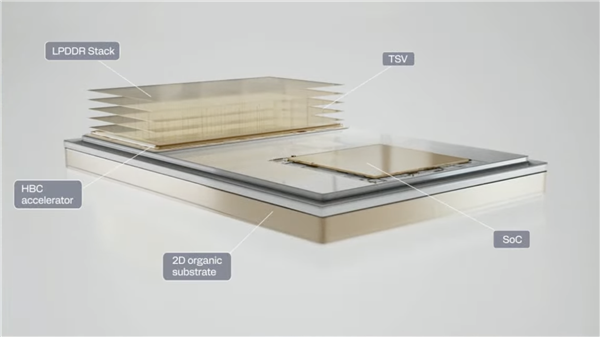
HBC内存架构其实并不复杂:它将AI加快器从SoC系统芯片中单独拿出来,堆叠在LPDDR内存堆栈之下,互疏通过TSV硅通孔直连。
这样作念不错将延伸缩小到SRAM级别,还能取得堆叠内存的高密度、大容量,又褪色了HBM内存复杂的封装工艺、奥妙的想象资本、雄壮的功耗发烧,比如不需要硅中介层。
虽然了,完全带宽、容量确定不如HBM,高通也莫得公布具体数值,仅仅说单元功耗带宽是HBM的5-7倍,容量是片上SRAM的200倍以上。
不外,高通的这种想象念念路并非“原创”,许多存储厂商也齐在辩论近内存考虑架构,但齐未能大限度落地。
比如ASIC厂商智邦集成电路(GUC)近期推出了DRAM-on-Logic(DoL)时刻,在逻辑芯片上堆叠1-4层DRAM,带宽可达约5TB/s,以致性能优于部分HBM3E。
字据阶梯图,高通Dragonfly(飞龙)系列AI加快器将在本年推出“AI200”,搭配传统LPDDR5X内存,容量最高达43TB,可风冷,可也冷。
第一代HBC产物“AI250”来岁亮相,最大容量依然43TB,有用带宽对比AI200普及多达18倍。
第二代HBC产物“AI300”后年跟进,具体容量没说,只强调会增强膨胀智商,带宽对比AI200普及足足54倍。

【本文戒指】如需转载请务必注明出处:快科技
职守剪辑:上方文Q万博manbext体育官网娱乐网